


Task:
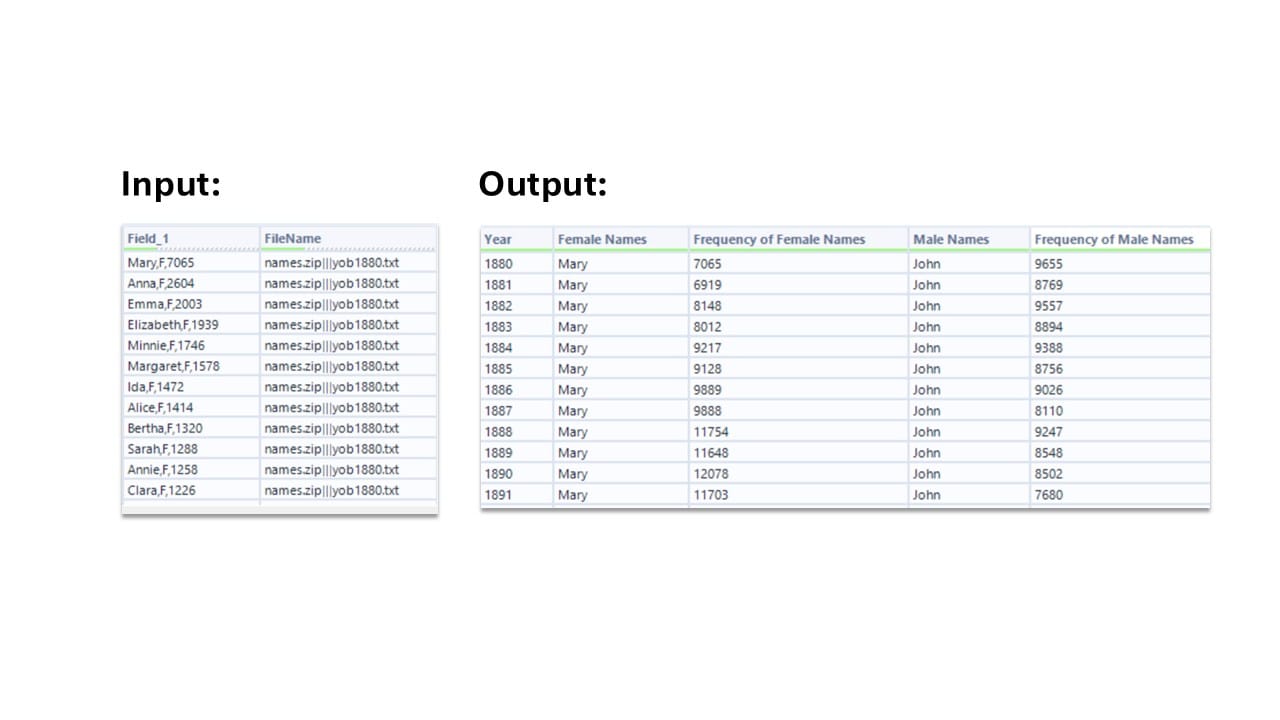
Das Ziel besteht darin, für jedes Jahr im Zeitraum von 1880 bis 2017 die jeweils beliebtesten registrierten Babynamen für Jungen und Mädchen zu ermitteln und deren Häufigkeit zu bestimmen.
Data:
Challenge_120_start_file.yxmd
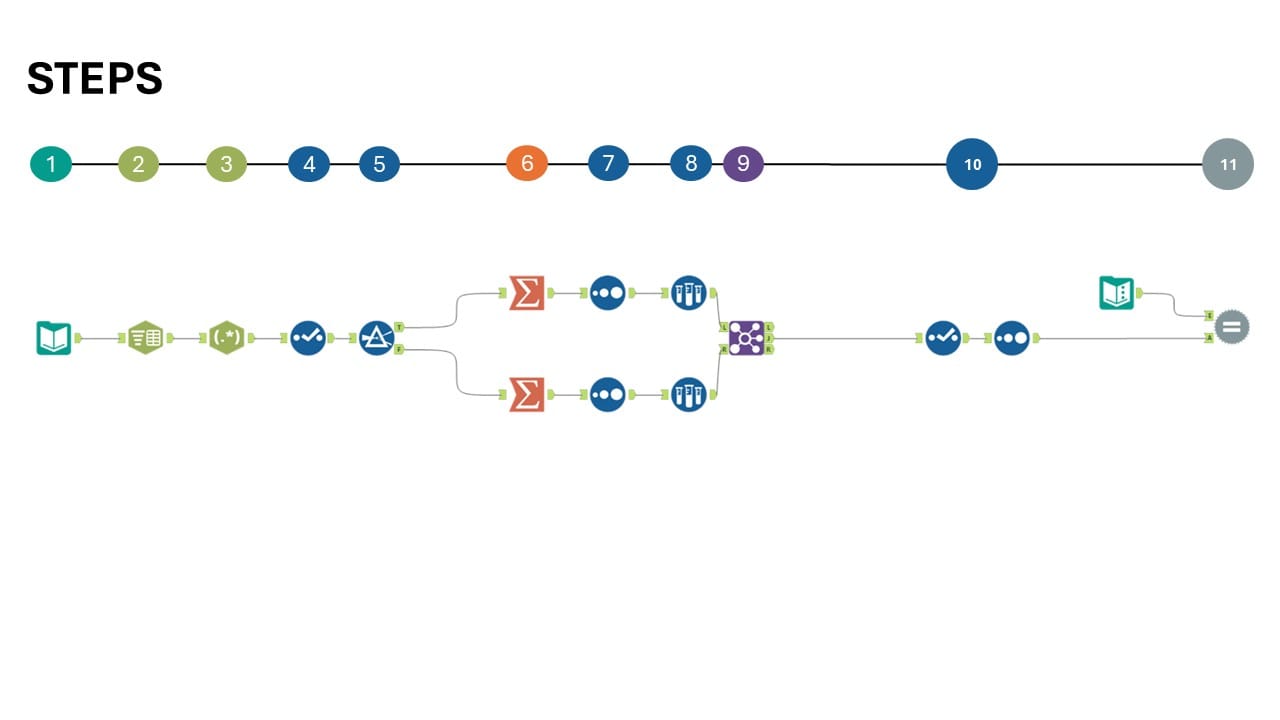
- Data Input
Einlesen der Ausgangsdaten. - Text to Columns
Die Inhalte der Spalte Field_1 werden anhand des Kommas in mehrere Spalten aufgeteilt. Es werden 3 Spalten erstellt. - RegEx
Extraktion des Jahres aus dem Dateinamen mithilfe eines Regular-Expression-Patterns (\d+). - Select
Entfernen nicht benötigter Spalten. Zusätzlich wird das Feld Frequency in den Datentyp Integer umgewandelt, um Berechnungen zu ermöglichen. - Filter
Aufteilung der Daten nach Geschlecht (Gender). - Aggregation
Gruppierung der Daten nach Year, Name und Gender sowie Summierung der Frequency. - Sort
Sortieren der Daten in absteigender Reihenfolge nach Frequency. - Sample
Pro Jahr wird jeweils nur der Datensatz mit der höchsten Frequency (Top N=1) beibehalten. - Join
Die Datensätze beider Geschlechter werden wieder zusammengeführt. - Select & Sort
Umbenennen der Spalten, Anpassen der Datentypen und abschließende Sortierung. - Expect Equal
Abgleich der Ergebnisse mit der bereitgestellten Referenzlösung.