


In this blog, I talked about using python decorators to wrap my API call to Amplitude in retry logic. That script saved the contents of the API to my local directory.
To build a standalone pipeline, however, I needed a way to automatically run my script either on a schedule or through a trigger. I used a tool called Kestra to achieve this.
What is Kestra?
Kestra is an open-source declarative data orchestration platform. With its combination of a user-friendly UI and YAML-driven configuration, Kestra is an accessible platform that almost anyone can pick up.
Setting Up Kestra in Docker
I set up a local Docker container in which to run Kestra, so I’ll briefly introduce Docker as well. Docker is a platform for building, shipping, and running applications in containers. Putting it in a different way, Docker allowed me to create a portable, packaged Kestra and run it in isolation without worrying about installation, dependencies, and environment differences. My Docker container was configured by a docker-compose.yml file, which told Docker how to build the container and what to include. By running the command docker-compose up in Docker, I had a locally hosted Kestra instance ready for use.
Creating a Flow in Kestra
In Kestra, a flow is the fundamental unit of orchestration in Kestra. Within a flow, you can define a set of tasks, their execution order, inputs, outputs, and orchestration logic.
When you create a flow, you’ll be presented with a yaml Flow Code template. This yaml code dictates the logic for the flow. Within this flow, we can add tasks that will run when we execute this flow.

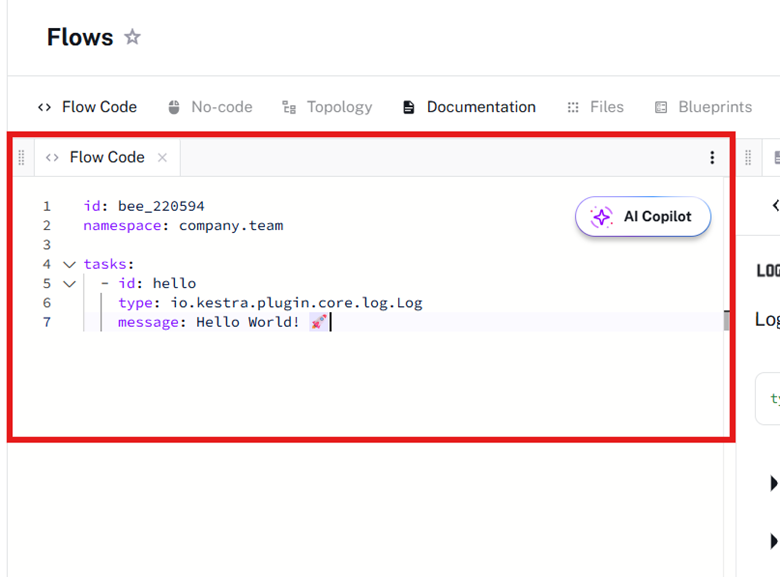
YAML can be very finicky. Indentation, spacing, and spelling can make or break your YAML. Luckily, Kestra has a graphical way to add to your YAML.
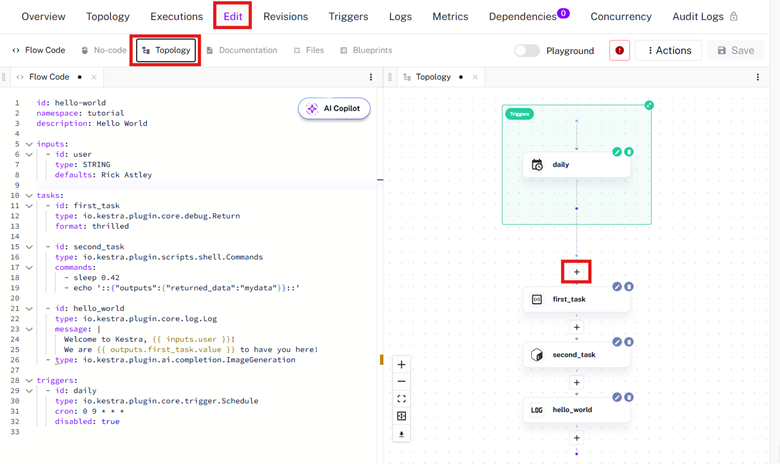
With the flow open, select Edit and Topology. Press + in the topology to automatically generate YAML for a task. Any configuration you add to the task will also be added to the YAML.
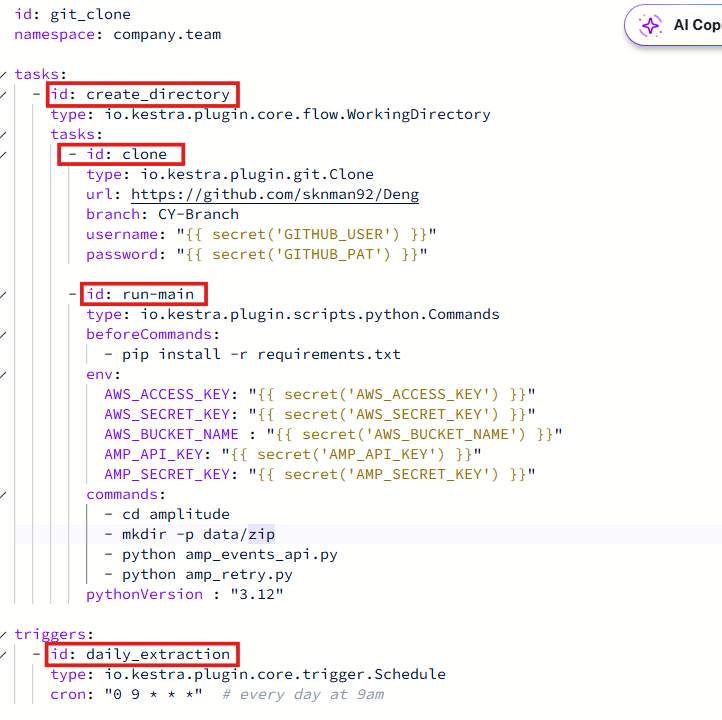
Kestra Flow for Amplitude API
For my flow, I wanted to achieve the following main objectives:
- Create a working directory in which to temporarily store the files from the API
- Within this task:
a. Clone my Github repository that contains the Amplitude API script
b. Install requirements for the script to run
c. Run my script - Finally, I added a trigger block at the end so that my flow would run every day at 9 am.
Here’s what the final YAML for my flow looked like -
Conclusion
Kestra (and Docker) are free, open-source tools that you can use to start orchestrating your projects. Hope this blog gave you some ideas on how to schedule your data pipeline!