Have you heard of ETL, ELT, Reverse ETL process? What do they mean?
Those are data integration patterns that describe how data moves through a data pipeline, where it is transformed, and how it is used across an organization. The pattern sounds similar, but they serve different purposes in the modern data structure.
1/ ETL (Extract, Transform, Load)
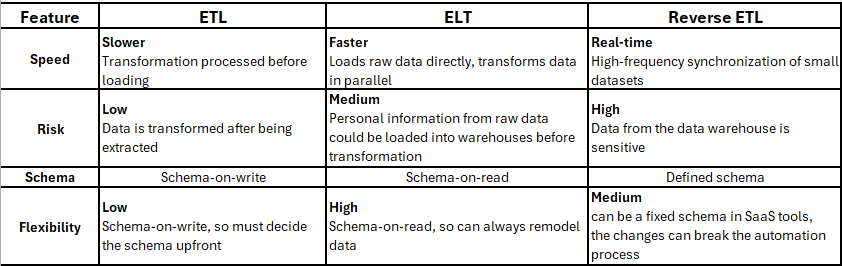
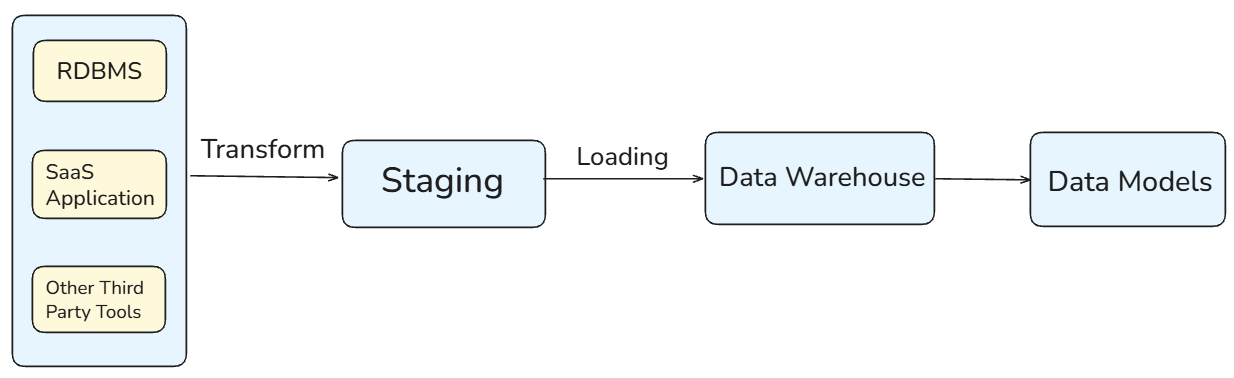
The name of this method refers to the order of the process. Data is first extracted from source systems, then transformed in a staging or processing layer, and finally loaded into the data warehouse.
In ETL, the schema is enforced early (schema-on-write). Data must conform to a predefined structure before it can be loaded into the warehouse.
Pros:
- The data is cleaned and validated before loading
- Strong data quality and consistency
- Lower risk of storing raw or sensitive data
- Easier governance and compliance in legacy systems
Cons:
- Slower ingestion as transforming data before loading
- Less flexible when business requirements change
- Scaling transformations can be expensive
- Reprocessing historical data is difficult
Great to use when:
- Legacy data warehouses are in place
- Strict governance or regulatory requirements exist
- Reporting requirements are stable
- Compute resources are limited inside the warehouse
2/ ELT (Extract, Load, Transform)
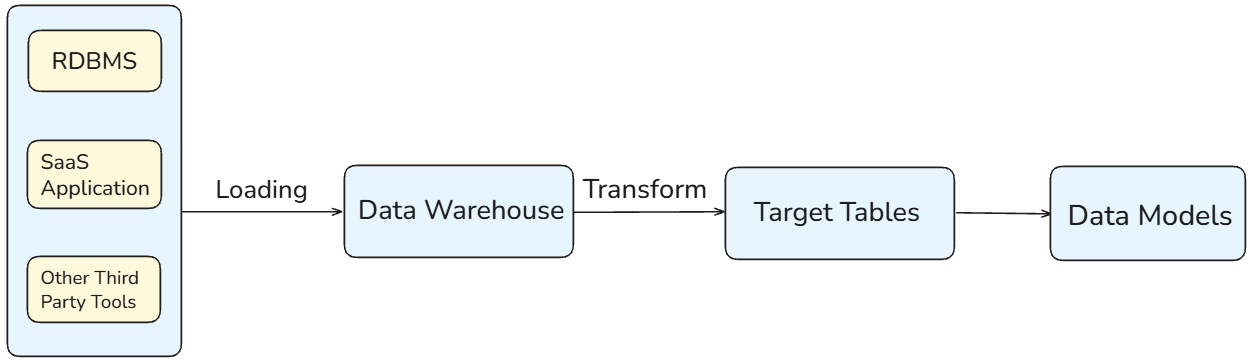
In ELT, data is extracted from source systems and loaded directly into the data warehouse as raw data. Transformations occur after loading, inside the warehouse, to produce target tables and data models.
This pattern follows schema-on-read, where the structure is applied when data is queried or modeled.
Pros:
- Faster data ingestion as the transformation process is after loading
- Highly flexible and scalable
- Easy to retransform the historical data
- Ideal for analytics engineering and dbt workflows
Cons:
- Raw data may be messy
- Higher risk if the personal information is not governed (Raw data is loaded into the data warehouse)
- Requires strong access control and monitoring
Good to use when:
- Using modern cloud data warehouses (Snowflake, BigQuery)
- Handling large volumes and unstructured data
- Need flexibility and agility
- Need immediate access to data. Good for Analytics and BI.
3/ Reverse ETL
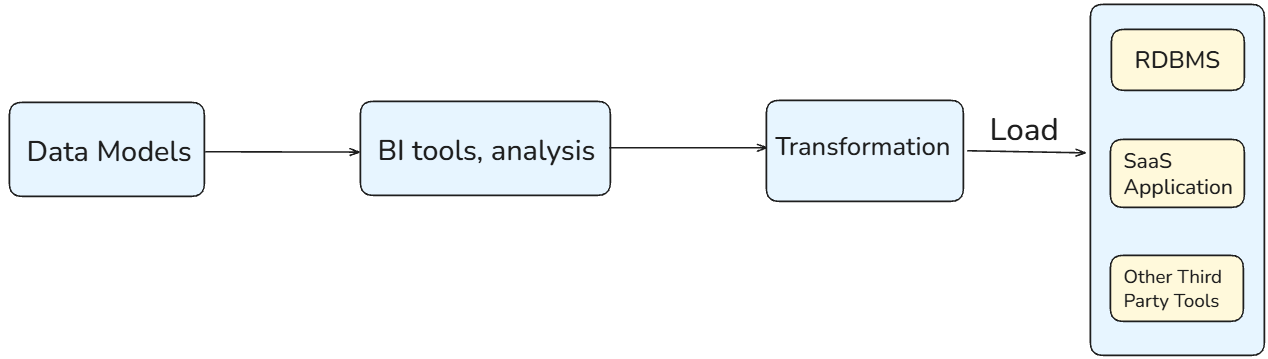
Reverse ETL is a newer process. It will reverse the ETL process. From the data models, through the BI tools and analysis (for example, Tableau or Power BI), the company needs the analysis data to make informed decisions. Now, the data is extracted from there with a transformation before loading it to the SaaS application (E.g, Salesforce).
Pros:
- Turn analytics into real business actions
- Keeps operational tools in sync with the warehouse
- Data is consistent and accurate
- Reduces data silos across teams
Cons:
- Requires strong data modeling discipline
- Risk of spreading sensitive data across systems
- Debugging issues can be more complex
Good to use when:
- Optimizing and automating marketing campaigns
- The team needs operational consistency
- Real-time decision-making is required in SaaS tools
- The insights must drive action in CRM, marketing, or support tools
Comparison Table between ETL, ELT, and Reverse ETL
Depending on the organization’s goals and use cases, teams can choose the appropriate data integration patterns to design their data pipelines.