


Unlike most programming languages, SQL queries are not executed in the order in which they are written. This blog focuses on the difference between writing order and execution order. Understanding the differences between the two is essential for writing correct queries.
Writing vs Execution
SQL queries are written in a simple, top-to-bottom structure. A typical query might be written using the following keywords and order:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
This is the writing order - the structure used to express the query. This is not, however, the order in which the database processes it. The execution order is instead:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
SQL does not begin by deciding which columns to return, as might be implied by needing to SELECT at the start of a query. Instead, it first needs to identify what tables to look in, which it then filters, groups by if required, and only then determines which columns to output.
Briefly describing what each clause does in the context of execution:
FROM: identifies the tables and performs joins, if specified
WHERE: filters rows based on conditions
GROUP BY: aggregates rows
HAVING: filters the aggregated rows
SELECT: computes and returns the final columns
ORDER BY: sorts the rows
Each step is dependent on the output of the preceding step. If something has not yet been created in this sequence, it can't be referenced.
Aliasing and Execution Order
The inability to reference column aliases, made in the SELECT clause, later in the writing order is a common point of confusion. Consider the following query:
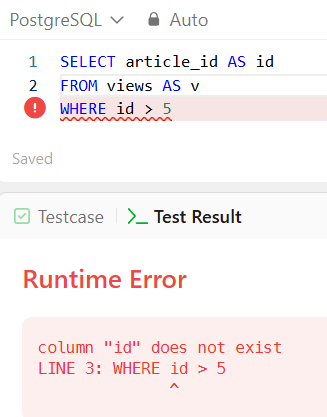
Depending on the flavour of SQL, queries referencing aliased columns within the WHERE clause will fail. The WHERE clause is evaluated before the SELECT clause, meaning that the alias 'margin' has not yet been defined at the point that the filtering in WHERE is applied.
In order to make the above query evaluate within PostgreSQL, the un-aliased column name - 'article_id' - must be used in place of the aliased 'id' within the WHERE clause.
This aligns with the order of execution: the WHERE filtering happens before column selection/aliasing.
Issues with aliasing are flavour-dependent. In Snowflake, an analogous query to the one above (i.e., one in which a column alias is referenced in the WHERE clause) will execute.
This does not mean that Snowflake evaluates SELECT before WHERE, but that Snowflake is being permissive. It rewrites or resolves the query internally so that the alias can be used earlier than it would otherwise exist.
But, this behavior is not consistent across SQL flavours. Queries that rely on aliasing in WHERE may work in Snowflake, but not in other systems. As such, it is generally safer to write queries that respect the execution order, even if your preferred flavour allows for shortcuts.
Aggregation and Execution Order
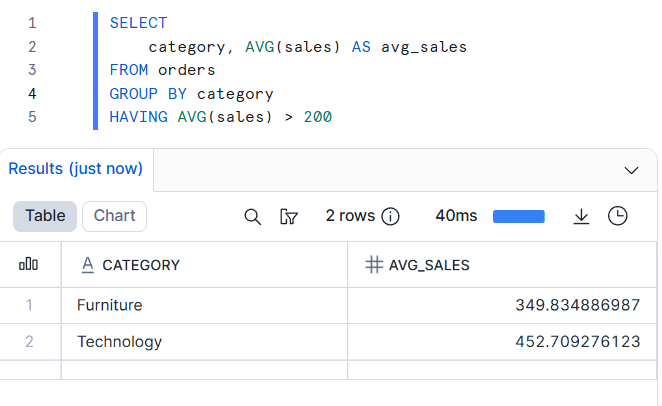
Execution order helps to explain the distinction between the WHERE and HAVING clauses. Consider the following query:

Which will fail across all SQL flavours as the WHERE clause is evaluated before any grouping or aggregation. At the point where the WHERE is applied, the average sales per category has not yet been computed.
The HAVING clause must be used to filter the aggregated rows:
Grouping and Execution Order
The order of execution also explains why, when using GROUP BY, every column in the SELECT clause must either be aggregated or included in the grouping. As grouping by occurs before column selection, only values that define that group, or values that are derived from it, can be returned.
Take the following query:

Which will fail in every SQL flavour. After grouping by Category, there is no single, well-defined value for Sub-Category within each group. Each category may, and will in this case, contain multiple sub-categories, and the database cannot determine which value to return.
To resolve the error, Sub-Category must either be included in the SELECT clause (which would return a row for every Category and Sub-Category), or it must be removed from the SELECT clause.
After a GROUP BY, any column in the SELECT clause must either identify the group, or be computed from it using an aggregate function.
Takeaway
- SQL queries are executed in a different order to which they are written.
- Each clause operates on the result of the previous step.
If something has not yet been computed, it cannot be referenced. - WHERE filters rows before aggregation, while HAVING filters after.
- GROUP BY changes the shape of the data.
After grouping, only grouped columns or aggregated values can be selected. - Some SQL flavours, such as Snowflake, allow shortcuts (e.g. aliasing in WHERE or HAVING).