


Protecting People and Privacy in Data
Personally Identifiable Information (PII) has long been a primary concern of data privacy—a clear, defined set of attributes that data professionals, governments, and citizens strive to protect. Government-issued identifiers, financial data, biometric data, authentication credentials; all of these kinds of data are things we are used to protecting.
And at this point in the history of internet-enabled society, most of us have felt the pain caused by the proliferation of this kind of data. Nearly anyone who has interacted with a computer has likely had personal information leaked (see here to check for yourself), and many of us have faced the headache (or worse) of identity/credit card theft.
To combat the mishandling of PII, strict laws and regulations now exist in most jurisdictions around the world, demanding that companies and agencies treat PII with the digital equivalent of a high-security vault.
”Traditional” PII and Data Obfuscation
Part one of this two-part blog series is about the longstanding methods of protecting PII.
From the perspective of a data engineer, protecting PII is about making sure no one can “see” sensitive data, while still ensuring it can move through a pipeline and be used as needed by developers and the relevant stakeholders.
To achieve this, we rely on a standard set of tools to strip away identity while maintaining utility and deploy them at strategic points in the data pipeline or development/production cycle.
Some questions to consider when choosing obfuscation tools and methods:
Does the masking method need to be reversible?
Are there points in my data pipeline that are more secure or less secure than others?
Does the raw PII need to be accessible to anyone? Who needs that access?
What kind of analysis is needed? How much tolerance is there for altering the data?
Do I want the raw PII to be written to disk anywhere in the pipeline or do I want only to use it in-memory.
Most importantly, knowing which tools to use when is crucial to making data obfuscation work in your pipeline.
When to do Masking
When should data masking happen in a data pipeline? The answer depends on how you answer the questions above, and beyond. See below for three main categories of data masking, as defined by the part of the modern ELT pipeline in which they occur.
Keep in mind, you might use different methods of masking at multiple points in your pipeline.
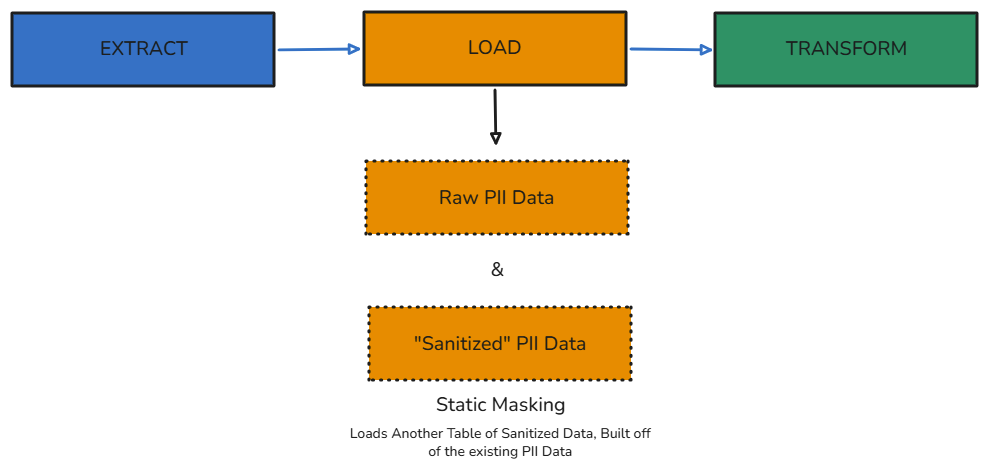
Static Data Masking
Take an existing database, full of sensitive data, and “sanitize” it using shuffling or substitution algorithms. Save the new sanitized data into a new database, which can then be used by (for instance) developer teams or testing processes.
In terms of the ELT pipeline, this essentially happens as a distinct Load step. The source data containing PII is still extracted and loaded separately.
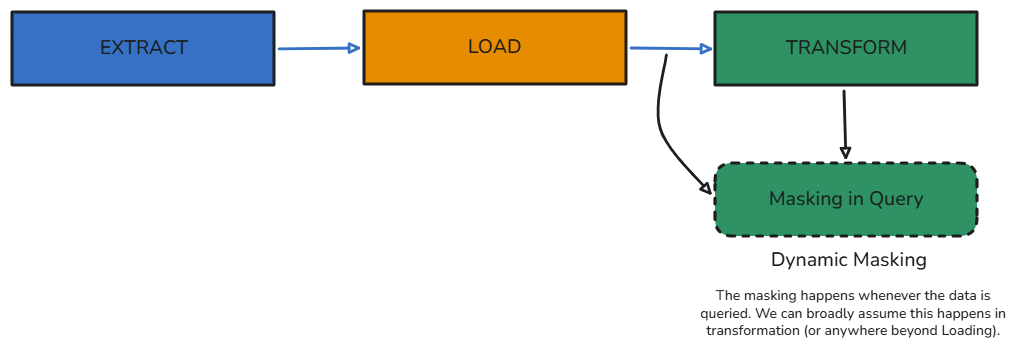
Dynamic Data Masking
Mask the data only when it is queried by a developer or a process. You’re not making a separate “sanitized” database, but rather applying the processes whenever the data is pulled in to be used.
This process would happen during or before the Transformation step of an ELT pipeline. The PII is already loaded somewhere from which it can be queried.
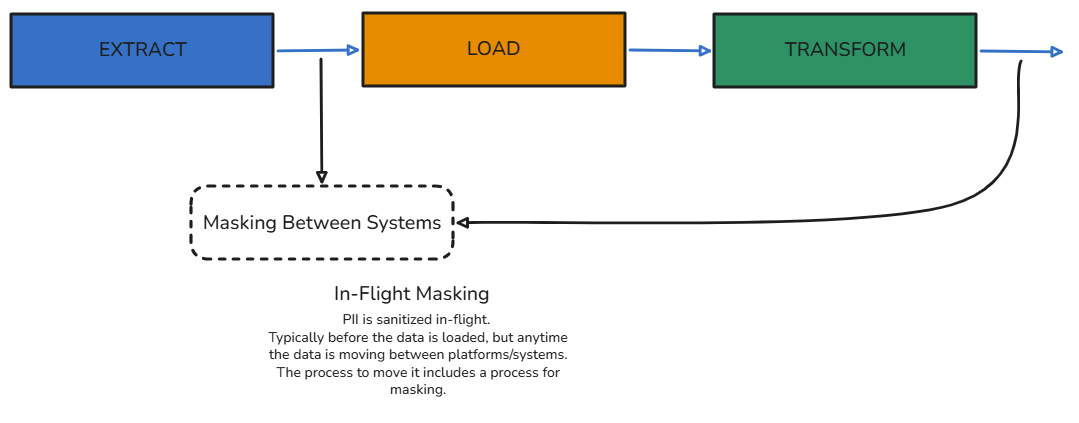
In-Flight Data Masking
Mask the data as it is extracted from the source system, before it is loaded anywhere else. This method can also be applied whenever the data is moving between systems, and relies on an in-memory process to do the masking before the data is ever written anywhere.
How to Do Masking
Tools and methods for Masking/Obfuscation of traditional PII are ubiquitous in modern data pipelines. See here for 5 different categories of methods, defined by their approach and the results they produce.
Cryptography and Tokenization
First on the list, since these methods are extremely common, used not only for protecting PII but also general data security. They are also reversible.
Encryption: You substitute real data with encrypted values. You can use deterministic (same input, same output), order-preserving, or format-preserving encryption to keep your data structures intact. Encryption requires a key and an algorithm to both encrypt, and then decrypt data.
Tokenization (Pseudonymization) replaces identifiers with a specific unique code. The mapping of values lives in a secure "vault." Tokenization requires a key and access to the lookup table that represents the vault.
There are Enterprise and Open-Source resources for the above, including:
Google Cloud Sensitive Data Protection (formerly DLP)
GnuPG (open-source)
Various Python libraries, like cryptogoraphy
Sampling and Aggregation
If your use-case doesn’t require row-level granularity or access to individual records, then consider statistical methods of masking. Sampling a representative subset of the data to analyze shrinks the exposure of sensitive data while maintaining meaningful insights. Aggregating groups data on related attributes. Instead of seeing that "User A bought coffee at 9:01 AM," you see that "1,400 coffees were sold in the 9:00 AM hour."
Example in SQL:
-- Aggregating to obscure individual transaction times
SELECT
DATE_TRUNC('hour', transaction_time) AS hour_block,
COUNT(user_id) AS total_users,
SUM(amount) AS total_revenue
FROM sales_data
GROUP BY 1;
Masking and Suppression
Sometimes the safest move is to simply redact. Suppression involves removing or hiding data points that are too sensitive or high-risk. You might mask a column across the board or drop specific "outlier" records that make a person too easy to identify. Masking involves replacing individual characters with meaningless placeholders.
Example in Python:
# Simple string masking for email addresses
def mask_email(email):
parts = email.split('@')
return f"{parts[0][0]}***@{parts[1]}"
# 'johndoe@email.com' -> 'j***@email.com'
Generalization and Anatomizing
You can protect identity by making the data "fuzzier" or structurally disconnected. Generalization reduces granularity. You turn "37" into "35-40." It preserves record-level accuracy but prevents unique identification. Anatomizing allows you to de-identify by splitting the data. You put the "Who" (Zip Code, Age) in one table and the "What" (Medical Diagnosis) in another. By breaking the direct link, you make re-identification significantly harder.
Example in SQL:
-- Generalizing exact ages into brackets
SELECT
CASE
WHEN age BETWEEN 18 AND 25 THEN '18-25'
WHEN age BETWEEN 26 AND 35 THEN '26-35'
ELSE '36+'
END AS age_group,
count(*)
FROM user_registry;
Randomization and Synthesis
For high-level analysis and ML, you might not need the raw data at all.
Randomization: You inject "mathematical noise." This obscures the original form and makes it nearly impossible to link back to an individual, though the dataset remains statistically relevant for broad trends.
Synthetic Data: You generate entirely artificial datasets that mirror the statistical patterns of the real world. It’s the gold standard for testing, provided your model doesn't accidentally recreate real people.
Coming Soon!
Part 2 of this blog series will cover the context and methods for data obfuscation related to Digital Fingerprinting and Behavioral Biometrics - relatively new areas of focus for data privacy and security.